Ob Rechnungen, Schriftverkehr, Verträge oder Serviceberichte – in vielen kleinen Unternehmen stapeln sich noch immer Papierdokumente oder unübersichtliche PDF-Dateien. Digitalisierung ist daher auch für kleine Unternehmen ein wichtiges Thema.
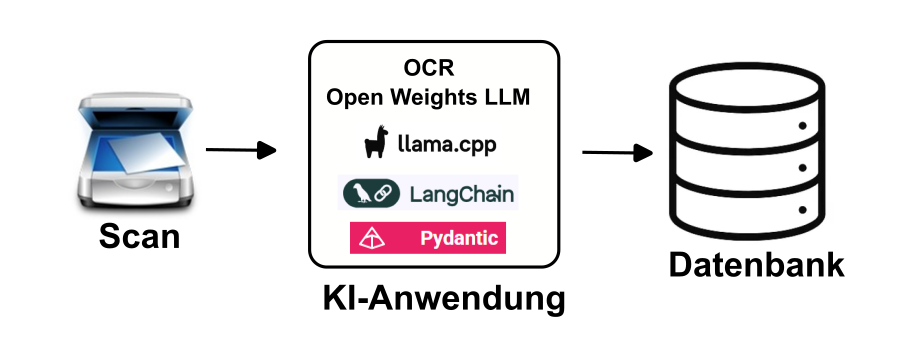
Doch nach dem Einscannen und der Verarbeitung mittels OCR hat man erst einmal nur unstrukturierten Text. Moderne KI-Modelle können daraus automatisch strukturierte Daten gewinnen und so Digitalisierungsprozesse unterstützen.
Stellen Sie sich vor:
- Hausverwaltungen digitalisieren alte Unterlagen wie Baugenehmigungen, Behördenschreiben oder Teilungserklärungen. Diese werden eingescannt, automatisch verschlagwortet und in einer Datenbank verfügbar gemacht – jederzeit durchsuchbar und ohne langes Aktenwälzen.
- Handwerksbetriebe erfassen Lieferscheine und Rechnungen automatisch, extrahieren Material- und Kostendaten und übertragen sie direkt in die Buchhaltung.
- Logistik- und Transportunternehmen lassen Frachtpapiere, Lieferscheine oder Zollunterlagen automatisch auslesen und in ihre Systeme einspielen – so werden Abläufe beschleunigt und Fehler reduziert.
Was bisher mühsame Handarbeit war, wird so zu einem effizienten, fehlerarmen Prozess – und schafft Freiräume für das Wesentliche: die Arbeit am Kunden, Projekt oder Transportauftrag.
Wie funktioniert die Technik dahinter?
Dank OpenSource Software und frei verfügbaren Open Weight-Modellen ist die Umsetzung eigener KI-Systeme heute nicht mehr nur großen Konzernen vorbehalten. Auch kleine Unternehmen können mit überschaubarem Aufwand maßgeschneiderte Lösungen entwickeln und diese im eigenen Serverraum (oder auch im Büro) selbst bereitstellen.
Die Extraktion strukturierter Daten aus unstrukturierten Dokumenten basiert dabei auf folgenden zentralen Bausteinen:
- Open Weights-Modelle: Zahlreiche KI-Firmen haben Gewichtsdateien („weights“, „Parameter“) ihrer Sprachmodelle veröffentlicht, so dass diese auf eigenen Computern lokal (z.B. mit llama.cpp) genutzt werden können. Dazu zählen: LlaMA-3, Mistral, gpt-oss-20B, Qwen3 und DeepSeek.
- LangChain: Ein Framework, das die Interaktion mit Sprachmodellen organisiert und komplexe Verarbeitungsketten ermöglicht – etwa das Zusammenspiel von OCR, Prompting und Datenvalidierung.
- pydantic: Ein Python-Toolkit, das sicherstellt, dass die extrahierten Daten in ein klar definiertes Schema passen (z. B. Rechnungsnummer = Zahl, Datum = gültiges Datumsformat). So entstehen aus Texten saubere, maschinenlesbare Datensätze.
- Gezielte Prompts: Durch präzise formulierte Anweisungen wird das Sprachmodell dazu gebracht, genau die relevanten Informationen zu extrahieren – etwa „Lies aus diesem Dokument die Vertragslaufzeit, die Kündigungsfrist und den Namen des Mieters aus“.
Das Ergebnis: Aus PDFs oder eingescannten Papierdokumenten entstehen strukturierte Daten, die direkt in Datenbanken, ERP- oder Buchhaltungssysteme übernommen werden können.
Die Digitalisierung von Dokumenten ist kein Hexenwerk – sie braucht nur die richtigen Werkzeuge. Mit KI-basierten Lösungen sparen Sie Zeit, minimieren Fehler und machen Ihre Daten zu einem strategischen Vorteil.
Live erleben: Extraktion von Kundendaten aus Impressumsseiten
Damit Sie sich ein Bild machen können, wie das in der Praxis aussieht, habe ich eine kleine Live-Demo vorbereitet. In diesem Beispiel können Sie selbst ausprobieren, wie aus Informationen aus Impressums-Seiten von Firmen in Sekunden ein strukturierter Datensatz z.B. für die Kundendatenbank wird.
Jetzt den nächsten Schritt gehen
Sie möchten erfahren, wie diese Technik konkret in Ihrem Betrieb eingesetzt werden kann? Dann nehmen Sie Kontakt mit uns auf – wir zeigen Ihnen, wie Sie mit KI Ihre Dokumentenprozesse vereinfachen und echte Effizienzgewinne erzielen.
Kontaktieren Sie mich jetzt für ein unverbindliches Beratungsgespräch!