KI-Systeme, insbesondere „große Sprachmodelle“ (Large Language Models, LLMs), können in jedem Unternehmen sowohl Mitarbeitern als auch Kunden enorme Vorteile bieten:
- Chat-Bots beantworten Fragen und unterstützen die tägliche Arbeit
- Programmier-Assistenten analysieren und generieren Quellcode
- RAG-Systeme („Retrieval Augmentet Generation“) unterstützen die Dokumenten-Analyse
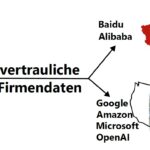
Doch es gibt viele Gründe, die Firmen davon abhalten, dafür z.B. die Cloud-Lösungen großer amerikanischer oder chinesischer Anbieter zu nutzen:
- Datenschutz: Kunden- und Mitarbeiterdaten bleiben innerhalb der eigenen Infrastruktur
- Compliance: Erfüllung regulatorischer Auflagen
- Betriebsgeheimnisse: internes Spezialwissen gelangt nicht nach außen
Die Lösung: Mit Open-Source-Software wie llama.cpp können Sie LLMs auf Ihren eigenen Servern betreiben.
In dieser Anleitung zeigen wir Ihnen, wie Sie mit überschaubarem zeitlichen und finanziellem Aufwand den ersten Schritt gehen können: einen eigenen Chat-Bot einrichten, mit Web-Interface und OpenAI-kompatibler API.
Dieser Text richtet sich an erfahrene Entwickler, die souverän mit Linux sowie mit Build-Tools wie CMake und Compilern umgehen können.
Wenn Sie in Ihrem Unternehmen Unterstützung bei der Einrichtung von KI-Systemen benötigen – sprechen Sie mich gerne an!
Hardware-Anforderungen: Einstieg ab 5.000 EURO
Die für KI-Anwendungen wichtigste und auch teuerste Komponente ist die Grafikkarte. Sie sollte über mindestens 24 GB Grafikspeicher (VRAM) verfügen. Je mehr VRAM zur Verfügung steht, desto größere Modelle können auf dem System laufen. In Frage kommt z.B. die NVIDIA RTX 5090 mit 32 GB VRAM. Die NVIDIA RTX 4090 wäre auch ok, ist aber neu kaum noch zu bekommen.
Der Arbeitsspeicher (RAM) sollte mindestens doppelt so groß sein wie der Videospeicher (mindestens 48 GB). Auch auf genügend Festplattenspeicher (bzw. SSD) sollte geachtet werden (mindestens 2 TB).
Hier ein Beispiel für ein Gesamt-System, welches je nach Anbieter zwischen 5.000 und 6.000 EURO kostet:
- Grafikkarte: NVIDIA RTX 5090
- Prozessor: Intel® Core™ i9-14900K
- 96 GB RAM
- 2x 4 TB SSD
Mit einem solchen System ist ein Einstieg möglich.
Wenn man größere Modelle betreiben möchte oder diese selbst trainieren möchte, ist evtl. leistungsstärkere (und damit teurere) Hardware nötig.
Bei einem System mit 48 GB VRAM (mit NVIDIA RTX A600) muss man mit über 8.000 Euro Anschaffungskosten rechnen. Falls noch mehr Grafikspeicher benötigt wird, können mehrere Grafikkarten gemeinsam verwendet werden. Weitere Infos zu Hardwarekosten gibt es hier.
Betriebssystem
Generell wird für Server-Anwendungen häufig Linux eingesetzt. Als Distributionen kommen z.B. Ubuntu, Arch oder Debian in Frage. In dieser Anleitung verwenden wir Debian 12 (Bookworm).
NVIDIA-Treiber installieren
Um LLMs auf der Grafikkarte (GPU) laufen zu lassen, ist ein aktueller NVIDIA-Treiber nötig. Informationen und Download-Links finden sich auf der NVIDIA-Homepage:
https://www.nvidia.com/de-de/drivers/unix/
Zum Installieren des NVIDIA-Treibers sind auch Kernel-Header für den aktuell installierten Linux-Kernel erforderlich.
# Als root:
# Linux Kernel Version prüfen
uname -r
# Header für aktuellen Linux-Kernel installieren
apt install linux-headers-$(uname -r)
# NVIDIA driver installieren
chmod u+x NVIDIA-Linux-x86_64-570.153.02.run
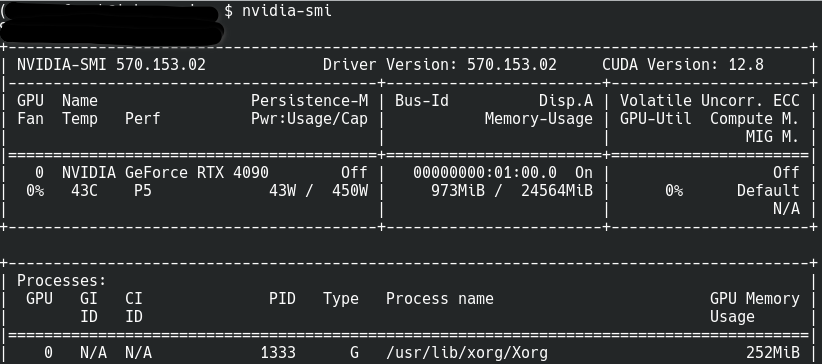
./NVIDIA-Linux-x86_64-570.153.02.runMit dem Tool nvidia-smi kann die Version des NVIDIA-Treibers und die CUDA-Version geprüft werden. Hier ein Beispiel für den Output:
NVIDIA CUDA-Toolkit installieren
Stellen Sie sicher, dass NVIDIA-Treiber und CUDA-Toolkit kompatibel sind.
Informationen zur Kompatibilität finden sich hier:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
Auf folgender URL finden sich Download-Links zu verschiedenen Versionen des CUDA-Toolkits, wo man die passende Version herunterladen kann.
https://developer.nvidia.com/cuda-toolkit-archive
Dort werden z.B. für Debian verschiedene Möglichkeiten der Installation angeboten.
Für einen direkt mit dem Internet verbundenen Rechner empfiehlt sich die Variante deb (network):
wget https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb
dpkg -i cuda-keyring_1.1-1_all.deb
apt-get update
apt-get -y install cuda-toolkit-12-8Um das CUDA-Toolkit verfügbar zu machen, ist es sinnvoll, in der .bashrc folgende Umgebungsvariablen zu setzen:
# make cuda available
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATHNach der Installation kann die Version geprüft werden mit:
nvcc --version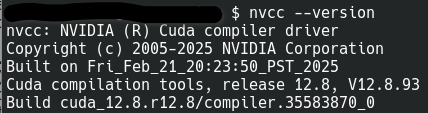
LLM einrichten
Software-Voraussetzungen
Folgende Software sollte auf dem System bereits eingerichtet sein und wird in diesem Tutorial vorausgesetzt. Die in Klammern angegebenen Versionsnummern geben Beispiele wieder, die zum Zeitpunkt der Erstellung dieses Artikels funktioniert haben:
- CMake (3.25.1)
- gcc (12.2.0)
- NVIDIA-Treiber (570.153.02)
- CUDA-Toolkit (12.8)
- git (2.39.5)
- libcurl4-openssl-dev
llama.cpp kompilieren
Zunächst legen wir ein eine Verzeichnisstruktur für Sourcecode, Build-Verezeichnis und Installation an:
cd
export LLAMA_DIR=$HOME/setup_llama_cpp
export LLAMA_BUILD=$LLAMA_DIR/build
export LLAMA_INSTALL=$LLAMA_DIR/install
mkdir $LLAMA_DIR
mkdir $LLAMA_BUILD
mkdir $LLAMA_INSTALLllama.cpp kann aus diesem Github-Repository gecloned werden:
cd $LLAMA_DIR
$ git clone https://github.com/ggml-org/llama.cpp.gitUm llama.cpp so zu kompilieren, dass die KI-Modelle auf der Grafikkarte berechnet werden können,
muss der Pfad zum CUDA-Toolkit in der PATH-Variable enthalten sein:
export CUDA_HOME="/usr/local/cuda-12.8"
export PATH=$PATH:$CUDA_HOME/binNun können wir llama.cpp übersetzen und installieren:
cd $LLAMA_BUILD
cmake -DGGML_CUDA=ON -DCMAKE_INSTALL_PREFIX=$LLAMA_INSTALL $LLAMA_DIR/llama.cpp/
cmake --build . -j 30
make installMit folgendem Befehl prüfen wir, ob llama-server prinzipiell startet:
cd $LLAMA_INSTALL/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$LLAMA_INSTALL/lib
./llama-server --helpSprachmodell auswählen und herunterladen
Frei verfügbare („open weights“) Sprachmodelle (LLMs) können z.B. von der Website ‚Hugging Face‘ heruntergeladen werden: https://huggingface.co/
Mit einer RTX 4090 Karte kann man z.B. Modelle mit 32 Milliarden Parametern („32B“, im englischen „Billion“) in einer auf 4 Bit quantisierten Version betreiben.
Ein interessantes Modell ist z.B. Qwen3:
https://huggingface.co/Qwen/Qwen3-32B-GGUF
Die .gguf-Datei laden wir nach $HOME/my_models herunter.
Nun können wir das Model mit llama-server starten:
export MODEL=$HOME/my_models/Qwen3-32B-Q4_K_M.gguf
export CTX=9000
export NGL=65
export PORT=8001
./llama-server -m $MODEL --port $PORT -ngl $NGL -c $CTXMit dem Parameter „--port“ kann festgelegt werden, auf welchem Port wir das Web-Interface im Browser öffnen können.
Der Parameter „-ngl“ legt fest, wie viele Schichten (layers) des Modells maximal in den Speicher der Grafikkarte geladen werden. Damit die Textgenerierung in akzeptabler Geschwindigkeit funktioniert, sollten der Wert so groß sein, dass alle Schichten in den Grafikspeicher geladen werden.
Das Qwen3-Modell wurde mit einem Kontextfenster von 40960 Tokens trainiert. Um es mit einem so großen Kontextfenster zu betreiben, reichen jedoch die 24 GB VRAM einer RTX 4090 nicht aus. Mit dem Parameter „-c" begrenzen wir daher die maximale Größe des Kontextfensters 9000 Tokens.
Sollte der Wert zu hoch gewählt sein, beendet sich der Server mit einer Fehlermeldung: „cudaMalloc failed: out of memory„. Dann muss man den Wert so weit reduzieren, bis der Speicher ausreicht. Wenn der Server erfolgreich startet, kann man im Browser die Web-Oberfläche starten: http://localhost:8001/
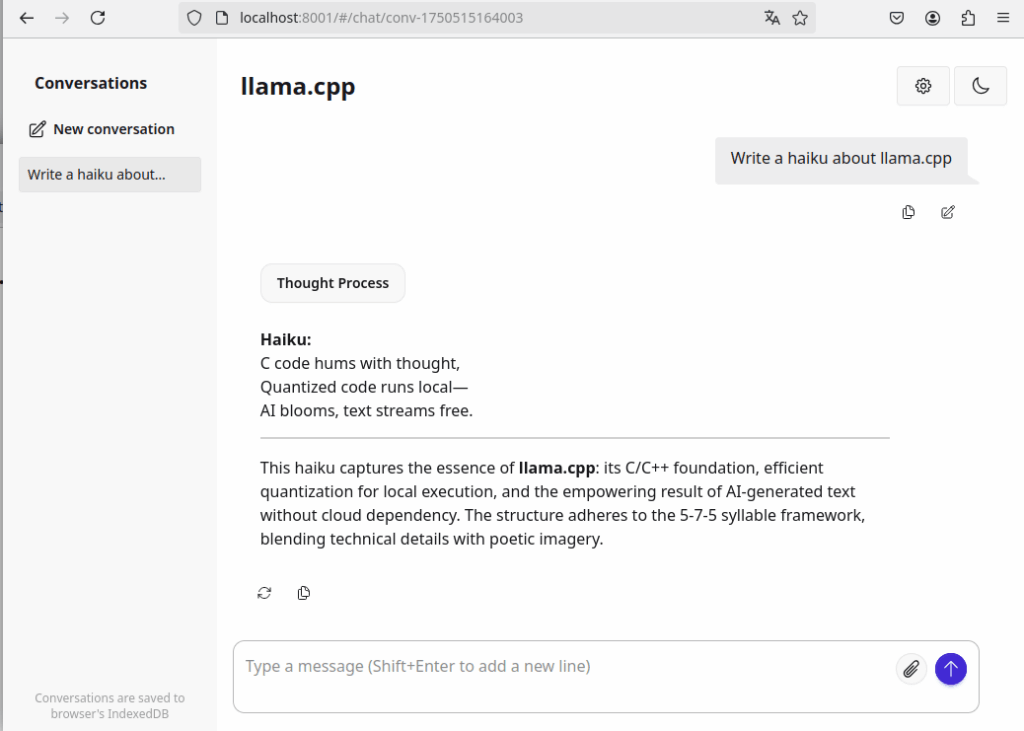
Neben dem Web-Interface kann llama.cpp auch über eine OpenAI-kompatible API angesprochen werden. Hier ein Beispiel, wie man diese mit curl testen kann:
curl -X POST http://localhost:8001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"}
],
"max_tokens": 20
}'Fazit und Ausblick
Nach dieser Installation sind wir in der Lage, verschiedene Sprachmodelle auf unserer eigenen Hardware auszuführen und sie sowohl über den Browser zu nutzen als auch sie aus anderen Programmen heraus über die API anzusprechen.
Mögliche nächste Schritte sind:
- Einrichten einer auf systemd basierenden Infrastruktur, um zwischen verschiedenen KI-Tools zu wechseln,
- Dokumenten-Analyse mit Retrieval Augmentet Generation (RAG) -Workflows
- und die Kombination verschiedener KI-Tools mit Agenten.
Falls Sie in Ihrem Unternehmen solche Projekte umsetzen möchten und Unterstützung benötigen – kontaktieren Sie mich!